
What would you do if I told you that nearly a third of your team’s time, every single day, is being thrown into a black hole? Not spent on innovation. Not driving revenue, not delighting customers.
Just… wasted.
I’m referring to the hours your analysts might currently be spending chasing down why the numbers don’t add up. The time your data engineers burn fixing broken pipelines instead of building the next game-changing model. The endless meetings where executives debate which version of the truth is actually true.
In today’s digital enterprises, data is supposed to be currency. But when that currency is counterfeit, the cost is staggering. Studies show that nearly one-third of enterprise time is consumed by poor-quality data: validating it, correcting it, reconciling it, and re-running processes that should have been automated, trusted, and insight-driven from the start.
This isn’t just a technical problem. It’s a productivity crisis hiding in plain sight. And it’s time we talked about it.
Poor Data Quality: The Silent Killer of Enterprise Productivity
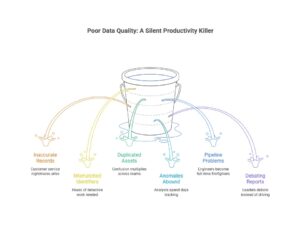
Here’s what poor data quality actually looks like on the ground:
- Every inaccurate customer record becomes a customer service nightmare.
- Every mismatched identifier creates hours of detective work.
- Every duplicated asset multiplies confusion across teams.
I’ve watched analysts spend entire days tracking down anomalies instead of uncovering insights. I have seen data engineers become full-time firefighters, constantly fixing pipelines instead of optimizing models. I’ve sat in boardrooms where leaders spend more time debating reports than actually driving outcomes.
The worst part? It compounds silently.
Poor data doesn’t announce itself with alarms and flashing lights. It seeps into your systems gradually, eroding confidence in decision-making and stalling operational efficiency one small failure at a time. Before you know it, your entire organization is moving slower, spending more, and nobody can quite pinpoint why.
The result? Reduced productivity that shows nowhere on your P&L. Higher costs disguised as “business as usual.” Blurred accountability because everyone’s working with different versions of reality.
Poor data quality creates an invisible tax on enterprise performance. And you’re paying for it every single day.
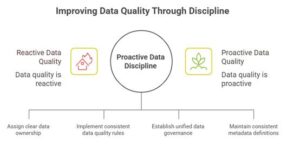
The Real Challenge: Poor Data Discipline
Here’s the uncomfortable truth I’ve learned after decades in this industry: the real issue isn’t just poor data. It’s poor data discipline.
Most organizations treat data quality like they treat fire extinguishers. You know you should have them; you might check them once in a while, but you only really think about them when something’s already burning.
Data quality becomes a reactive task rather than a proactive design principle. And that’s exactly backwards.
The root causes almost always include:
- Lack of ownership and accountability
- Absence of standardized quality rules
- Fragmented data governance
- Neglected metadata and inconsistent definitions
How Edgematics Builds Data Quality into Your DNA

At Edgematics, we believe high-quality data is the foundation of speed, trust, and transformation. And it has to be built in, not bolted on.
Our approach goes beyond simple data cleaning. We help you build a comprehensive Data Quality framework that becomes part of your organization’s DNA, powered by two game-changing platforms: PurpleCube AI for unified data engineering and Axoma for intelligent AI orchestration.
-
Continuous Profiling & Monitoring
Think of this as your data’s health monitoring system. With PurpleCube.ai, we set up continuous checks that detect anomalies early, before they cascade into bigger problems.
PurpleCube AI’s unified data engineering platform uses real-time GenAI assistance to automatically capture metadata and monitor your data pipelines. Instead of discovering data issues when reports break, you catch them at ingestion.
They’re early warning systems that protect your business. And with PurpleCube.ai’s self-healing capabilities, many issues get resolved automatically before they ever impact your operations.
-
Rule-Based Validation at Every Entry Point
We work with you to encode your business logic directly into your data pipelines. Using PurpleCube AI’s natural language interface, you can interact with the platform to generate data quality rules without writing complex code.
If a customer record needs a valid email and phone number, the system won’t accept it without them. If revenue figures need to match across systems, we validate that automatically. PurpleCube AI’s Data Quality Studio understand your business context and help create comprehensive validation rules that align with your data governance policies.
This isn’t about being rigid. It’s about being consistent. When data enters your ecosystem, it enters clean, or it doesn’t enter at all.
-
Golden Record Creation
Here’s a problem I see constantly: the same customer exists in five different systems with five different versions of their information. Different addresses, different phone numbers, different spellings of their name.
We help you create golden records. Single, unified, authoritative views of key entities like customers, products, and vendors. One source of truth that every system can trust.
-
AI-Powered Automated Corrections
Manual data correction doesn’t scale. This is where PurpleCube AI and Axoma work together brilliantly.
- Standardize addresses and phone numbers
- Detect and merge duplicate records
- Flag outliers that need human review
- Suggest corrections based on historical patterns
This dramatically reduces manual effort while improving accuracy. Your team focuses on exceptions that truly need human judgment, not mindless data entry.
-
The Immune System Approach
Together with strong data governance, these practices form what we call the “immune system” of the digital enterprise. Just like your body’s immune system detects, prevents, and cures infections before they make you sick, a robust data quality framework stops inconsistencies before they infect decision-making.
PurpleCube AI provides the unified data engineering foundation, ensuring all your data pipelines are optimized, monitored, and self-healing. Axoma adds the intelligent orchestration layer, deploying AI agents that work 24/7 to maintain data quality, respond to anomalies, and continuously improve your data ecosystem.
When your teams stop questioning whether they can trust the data, something magical happens. They start moving faster. They make bolder decisions. Which leads to innovations instead of verifying.
The Numbers Don’t Lie
I know what you’re thinking. “This sounds great, but what’s the actual ROI?”
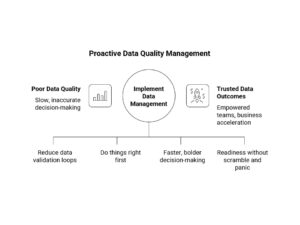
Organizations that invest in proactive data quality management report measurable, dramatic gains:
- Up to 40% faster project cycles because teams aren’t stuck in data validation loops
- 30% lower operational rework because things are done right the first time
- Higher trust in analytics and decision-making that translates to faster, bolder moves
- Improved regulatory compliance and audit readiness without the scramble and panic
But here’s what those numbers really mean in human terms:
Your analysts spend their days finding insights instead of finding errors. The data scientists build models instead of cleaning data. Your executives make decisions with confidence instead of hedging their bets because they’re not sure if the numbers are right.
In essence, trusted data fuels trusted outcomes. It empowers teams to innovate rather than verify. And that’s when businesses truly accelerate.
Building Data Confidence by Design
If you’re a leader reading this, here’s my challenge to you. Stop thinking about data quality as a technical problem that IT needs to solve. Start thinking about it as a strategic imperative that defines your competitive edge. The new mandate is Data Confidence by Design. That means embedding data quality at every stage of the data lifecycle, from the moment data is created or ingested all the way through to analytics and activation.
It means:
- Making someone accountable for data quality (and giving them the authority to enforce standards)
- Investing in the tools and platforms that make quality automatic, not manual
- Creating a culture where data quality is everyone’s job, not just the data team’s problem
- Measuring and reporting on data quality metrics just like you measure revenue and costs
This isn’t about achieving perfection. Perfect data doesn’t exist and chasing it will drive you crazy.
This is about building trust at scale. When teams across your organization trust the data they’re working with, they stop second-guessing themselves. They stop running manual checks. The team stops building shadow systems because they don’t believe the “official” numbers.
They start moving at the speed of insight instead of the speed of validation.

Reclaiming Your Lost Third
The bottom line is that poor data quality doesn’t just waste time. It wastes potential.
Every hour spent validating data is an hour not spent serving customers. Projects delayed by data issues create opportunities competitors might seize. Decisions deferred because “we need to check the numbers” result in lost momentum.
In an era where time defines a competitive edge, reclaiming that lost third isn’t optional. It’s existential.
The companies winning today aren’t the ones with the most data. They’re the ones with the most trusted data. They’re the ones who’ve built data quality into their DNA rather than treating it as an afterthought.
At Edgematics, we’ve seen firsthand what happens when organizations make this shift. The transformation is in the culture, the speed of decision-making, and the confidence with which teams execute.
Ready to reclaim that lost 30%? Let’s talk about how Edgematics can help you build trust in your data with PurpleCube AI for unified data engineering and Axoma for intelligent AI orchestration. Together, they create a powerful foundation for unified data and AI orchestration that transforms data quality from a reactive headache into a proactive competitive advantage.
Experience it yourself:
- Explore PurpleCube AI at www.purplecube.ai
- Discover Axoma at www.axoma.edgematics.ai
Together, let’s make a move toward unified data and AI orchestration – let’s chat.












