TL;DR:
- Automation in data workflows ensures end-to-end pipeline execution without manual intervention, enhancing reliability and compliance. Orchestration engines manage dependencies, retries, and observability, enabling resilient and transparent data processes crucial for enterprise success. Human oversight remains essential in interpreting signals, maintaining governance, and ensuring trustworthy automation at scale.
Automation in data workflows is defined as the orchestrated, end-to-end execution of data pipeline tasks — ingestion, validation, transformation, and delivery, without manual intervention at each stage. The role of automation in data workflows has shifted from a convenience to a foundational requirement for any enterprise operating at scale. Teams that still rely on manual scripts and cron jobs face compounding risks: missed SLA windows, silent data failures, and audit gaps that surface only during regulatory scrutiny. Platforms like Beta Systems, frameworks like DataOps, and tools like Soda have made CI/CD pipeline automation the standard practice for data engineering teams that need reliability and compliance built in from the start.
How orchestration engines drive automation in data workflows
Orchestration is the cognitive backbone of any automated data pipeline. Where cron jobs simply fire on a schedule regardless of upstream state, dependency-aware orchestration waits for upstream task success before triggering downstream steps. That distinction matters enormously in production environments where a failed ingestion job should never silently cascade into a corrupted reporting layer.
Modern orchestration engines handle four core functions automatically:
- Trigger management: Workflows fire on schedules, file arrivals, API events, or upstream task completion, removing the need for manual initiation.
- Dependency resolution: The engine maps task relationships and executes steps only when all prerequisites succeed, preserving correct sequencing.
- Retry logic: Failed tasks are retried with configurable back-off policies, reducing alert fatigue and preventing transient failures from becoming incidents.
- Observability: Real-time dashboards surface job status, SLA compliance, and failure alerts so engineers see pipeline health without querying logs manually.
The observability layer deserves particular attention. Orchestration platforms run ingestion, validation, transformation, and delivery automatically while providing the visibility teams need to meet SLA commitments. Without observability baked into the orchestration layer, automation becomes a black box. You gain speed but lose the ability to diagnose failures quickly, which is a trade-off no enterprise data team should accept.
Pro Tip: Checkout PurpleCube AI, Edgematics’ enterprise data orchestration platform.
The shift from manual scripts to AI-powered orchestration also changes how teams think about pipeline design. Instead of writing procedural scripts that assume a happy path, engineers define declarative workflows where the engine handles failure modes. That mental model produces more resilient pipelines from the first commit.
How does automation enforce data quality and compliance?
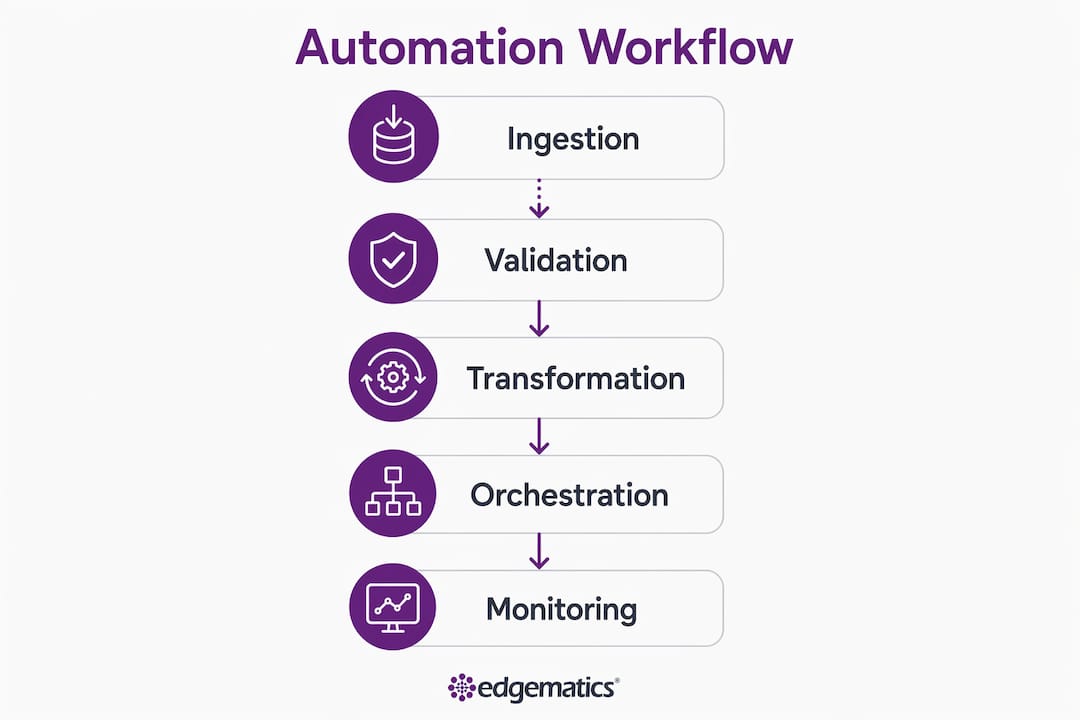
Data quality is not a post-processing concern. It is an enforcement problem, and automation solves it by placing validation gates at every stage of the pipeline lifecycle. Automated testing suites run schema checks, quality assertions, and freshness SLA validations at pre-commit, pull request, post-merge, and post-ingest stages, with severity-based responses ranging from blocking to quarantine to alert.
This approach shifts compliance from a retrospective audit exercise to a continuous, integrated practice. Consider what happens without it: a schema change in a source system propagates silently through three transformation layers before a downstream analyst notices that revenue figures are wrong. With contract enforcement in the CI/CD pipeline, that schema drift is caught at the pull request stage and blocked before it reaches production.
Key enforcement mechanisms that automated pipelines should include:
- Schema validation: Checks that incoming data matches the expected structure, catching column additions, type changes, and missing fields before they propagate.
- Quality assertions: Rules defined in tools like Soda verify that null rates, value ranges, and referential integrity meet thresholds set by data owners.
- Freshness checks: SLA enforcement confirms that data arrived within the expected window, flagging stale datasets before downstream consumers query them.
- Regression testing: Automated runs compare pipeline outputs against known-good baselines after any code change, catching unintended side effects.
Gating contract checks early in the pipeline reduces late discovery of data issues and limits downstream impact. The cost of fixing a data defect grows with every stage it passes through. Catching it at pre-commit costs minutes. Catching it after it has populated a production data warehouse costs days of remediation and erodes stakeholder trust..
Why human accountability still matters in automated pipelines
Automation does not eliminate the need for qualified people. It changes what those people are responsible for. Human oversight remains critical to interpret tool outputs, validate that automated checks are testing the right things, and maintain governance when edge cases fall outside what the tooling anticipated.
The risk of over-relying on automation without accountability is real. Vendors frequently market AI-driven data quality tools as self-managing systems that require minimal human involvement. That framing is misleading. Automated tools surface signals; humans must interpret them, act on them, and take responsibility for the decisions that follow.
Governance as code addresses this challenge at scale. Version-controlled governance policies covering access control, PII classification, and data retention are codified, tested, and deployed through the same automated pipelines as the data itself. This approach produces several concrete benefits:
- Policies are reviewed and approved through pull requests, creating a documented change history.
- Automated tests verify that governance rules are enforced correctly after every deployment.
- Policy drift, where production behavior diverges from documented intent, becomes detectable and correctable.
- Onboarding new data products into the governance framework requires configuration, not manual process design.
The layers of data governance that enable AI and analytics trust are not built by tools alone. They require engineers who understand what the tools are doing and can verify that the outputs are correct. Automation scales governance; people make it trustworthy.
Monitoring vs. auditing: what automated pipelines must support
Monitoring and auditing are distinct functions that automated pipelines must support independently. Conflating them is one of the most common governance gaps we see in enterprise data environments.
| Dimension | Monitoring | Auditing |
|---|---|---|
| Time orientation | Real-time, present state | Backward-looking, historical evidence |
| Primary question | Is the pipeline healthy right now? | Who changed what, and when? |
| Output type | Alerts, dashboards, SLA status | Durable records, access logs, change history |
| Failure response | Immediate remediation | Retrospective investigation and control verification |
| Compliance role | Operational health assurance | Regulatory proof and audit readiness |
Monitoring detects current health issues; auditing provides durable proof for compliance and retrospective controls. Both are necessary, but they require different automation strategies. A monitoring system that only retains 30 days of logs fails an auditor asking for 12 months of access records.
Data lineage automation sits at the intersection of both functions. Structural lineage, captured automatically by orchestration engines and transformation tools, maps how data moves between systems and tables. Semantic lineage is harder to automate because it captures the business meaning of transformations, not just their technical execution. Both layers are necessary for audit completeness.
Semantic lineage is frequently the gap that derails compliance reviews. An auditor asking why a specific customer record was excluded from a regulatory report needs to understand the business logic applied, not just the SQL that executed it. Automating the capture of semantic lineage through annotations in code, data catalog entries, and transformation documentation closes that gap before the auditor arrives.
Audit-ready pipelines require durable records of changes, access controls, and encryption maintained by automated processes. Manual record-keeping cannot match the consistency or completeness that automation provides at enterprise scale.
Key takeaways
Automation in data workflows succeeds when orchestration, contract enforcement, governance as code, and layered lineage tracking operate together as a unified system rather than isolated tools.
| Point | Details |
|---|---|
| Orchestration over scheduling | Use dependency-aware engines, not cron jobs, to prevent silent failures from cascading downstream. |
| Shift-left quality enforcement | Gate schema, quality, and freshness checks at the pull request stage to catch defects before they reach production. |
| Governance as code | Version-control access policies and PII rules so governance changes are auditable and testable like any other code. |
| Separate monitoring from auditing | Build both real-time observability and durable audit records into pipelines as distinct, non-interchangeable functions. |
| Human accountability is non-negotiable | Automated tools surface signals; qualified engineers must interpret outputs and own the decisions that follow. |
Our perspective on where automation in data workflows is heading
We have worked with data teams across banking, telecom, retail and more who believed they had solved their pipeline reliability problems by adopting an orchestration tool. What they discovered, often painfully, is that tooling adoption and automation maturity are not the same thing.
The organizations that get the most from data workflow automation share one characteristic: they treat their pipelines as products. That means version control, code review, automated testing, and documented ownership for every component. It also means resisting the temptation to automate processes that are not yet well-defined. Automating a broken process at scale produces broken outputs faster.
The emerging integration of agentic AI into orchestration is genuinely exciting, and we are actively building in that direction at Edgematics. AI agents that can detect anomalies, propose remediation steps, and escalate to human reviewers represent a meaningful step forward. But the prerequisite for that capability is a well-governed, well-documented pipeline foundation. You cannot build an intelligent nervous system on top of undocumented spaghetti.
The teams that will lead in 2026 and beyond are the ones investing now in data engineering and governance as a unified discipline, not as separate concerns owned by separate teams. Automation is the mechanism. Governance is what makes it trustworthy. Both require continuous iteration, not one-time implementation.
How Edgematics accelerates your automated data workflows
At Edgematics, with PurpleCube AI we build the end-to-end data infrastructure that makes automation reliable, auditable, and compliant by design. Our data engineering and governance solutions cover CI/CD pipeline automation, data contract enforcement, structural and semantic lineage tracking, and governance as code. We work with enterprise teams in healthcare, finance, and beyond to replace fragile manual processes with production-grade automated pipelines that hold up under regulatory scrutiny. If you are ready to move from ad-hoc scripts to a governed automation architecture, our data strategy services are the right starting point. Let’s build something that scales.
FAQ
What is the role of automation in data workflows?
Automation in data workflows replaces manual script execution and cron-based scheduling with orchestrated, end-to-end pipeline management that handles ingestion, validation, transformation, and delivery automatically. It improves reliability, enforces data quality, and builds compliance into the pipeline rather than adding it after the fact.
How does CI/CD automation improve data pipeline quality?
CI/CD automation runs schema validation, quality assertions, and freshness checks on every pull request, blocking bad data from reaching production. Automated testing layers catch defects at the earliest possible stage, where the cost of remediation is lowest.
What is the difference between monitoring and auditing in automated pipelines?
Monitoring tracks real-time pipeline health and surfaces active failures, while auditing produces durable, attributable records that verify controls were applied consistently over time. Both are required for enterprise compliance, but they serve different purposes and must be built as separate automation capabilities.
What is governance as code in data workflows?
Governance as code means version-controlling policies like access control, PII classification, and data retention rules, then deploying and testing them through the same automated pipelines as the data itself. This approach makes governance changes auditable, reversible, and verifiable at scale.
Why is semantic lineage harder to automate than structural lineage?
Structural lineage maps the technical movement of data between systems and is captured automatically by orchestration and transformation tools. Semantic lineage captures the business meaning of transformations and requires annotations, catalog entries, and documentation that engineers must author, making full automation a significant challenge but a critical one for audit completeness.











